Creating an AWS Lambda Function to Generate HLS Streams for Video Uploads to S3
In this blog, we’ll explore how to set up an AWS Lambda function to automatically create HLS streams when a video is uploaded to an S3 bucket. HLS (HTTP Live Streaming) is a popular streaming protocol, and it’s commonly used to deliver adaptive video streams that adjust to viewers’ internet speeds. By using Lambda and FFmpeg, we’ll automate the process of creating HLS streams at multiple resolutions.
Prerequisites
To follow along, you’ll need:
AWS Account with S3 and Lambda permissions.
FFmpeg static binary for your Lambda environment.
Basic familiarity with AWS Lambda and S3.
Let’s dive in!
Step 1: Prepare the FFmpeg Binary
AWS Lambda does not come with FFmpeg pre-installed, so we need to provide it ourselves. Here’s how:
Download FFmpeg static build: Go to FFmpeg’s website and download a static build suitable for your Lambda environment. AWS Lambda typically runs on Amazon Linux 2, so choose the Linux static build.
Make the Binary Executable: Ensure FFmpeg has the correct permissions:
chmod +x ffmpeg
- Test Locally: Run
./ffmpeg -versionto confirm that it’s working.
Step 2: Write the Lambda Function Code
Now, let’s write the Lambda function in Python to process video files and generate HLS streams at multiple resolutions.
lambda_function.py
import os
import boto3
import subprocess
# Initialize S3 client
s3_client = boto3.client('s3')
# Path to the FFmpeg binary inside the Lambda environment
FFMPEG_STATIC = "/var/task/ffmpeg"
# Define the target resolutions
RESOLUTIONS = {
"144p": "scale=-2:144",
"240p": "scale=-2:240",
"360p": "scale=-2:360",
"480p": "scale=-2:480",
"720p": "scale=-2:720",
"1080p": "scale=-2:1080"
}
def lambda_handler(event, context):
try:
# 1. Extract bucket name and object key from the event
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# 2. Download the video file from S3 to /tmp/
local_video_path = f"/tmp/{os.path.basename(key)}"
print(f"Downloading {key} from bucket {bucket}...")
s3_client.download_file(bucket, key, local_video_path)
# 3. Process the video into multiple resolutions
output_folder = f"/tmp/{os.path.splitext(os.path.basename(key))[0]}"
os.makedirs(output_folder, exist_ok=True)
# Create HLS segments for each resolution
for res, scale in RESOLUTIONS.items():
output_video_path = f"{output_folder}/{res}.m3u8"
ffmpeg_command = [
FFMPEG_STATIC, "-i", local_video_path,
"-vf", scale,
"-hls_time", "10", # 10-second segments
"-hls_list_size", "0", # Include all segments
"-f", "hls", output_video_path
]
print(f"Running FFmpeg for {res}: {' '.join(ffmpeg_command)}")
subprocess.run(ffmpeg_command, check=True)
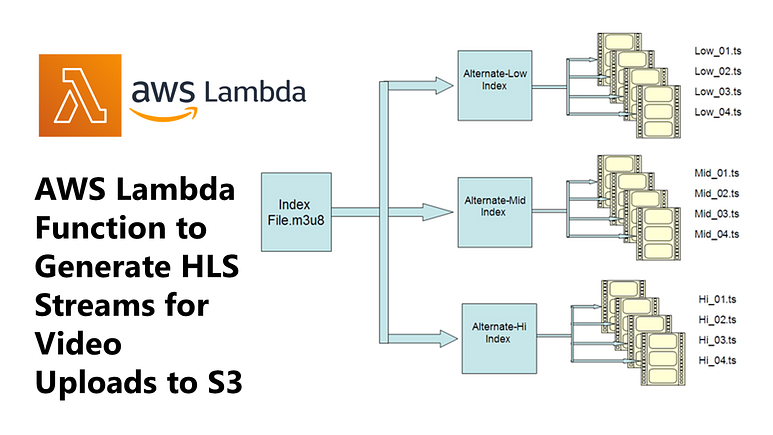
# 4. Generate a master HLS playlist
master_playlist_path = f"{output_folder}/master_playlist.m3u8"
with open(master_playlist_path, 'w') as master_playlist:
master_playlist.write("#EXTM3U\n")
master_playlist.write("#EXT-X-VERSION:3\n")
for res in RESOLUTIONS.keys():
master_playlist.write(f"#EXT-X-STREAM-INF:BANDWIDTH={get_bandwidth(res)},RESOLUTION={res}\n")
master_playlist.write(f"{res}.m3u8\n")
# 5. Upload processed files and HLS playlist to S3
for filename in os.listdir(output_folder):
file_path = os.path.join(output_folder, filename)
output_key = f"processed/{os.path.basename(output_folder)}/{filename}"
print(f"Uploading {file_path} to {bucket}/{output_key}...")
s3_client.upload_file(file_path, bucket, output_key)
return {
"statusCode": 200,
"body": f"Successfully processed and uploaded videos and HLS playlist for {key}"
}
except Exception as e:
print(f"Error: {str(e)}")
return {
"statusCode": 500,
"body": f"Error processing video: {str(e)}"
}
def get_bandwidth(res):
"""Calculate bandwidth for different resolutions."""
bandwidths = {
"144p": 300 * 1000, # 300 kbps
"240p": 600 * 1000, # 600 kbps
"360p": 1200 * 1000, # 1200 kbps
"480p": 1800 * 1000, # 1800 kbps
"720p": 2500 * 1000, # 2500 kbps
"1080p": 5000 * 1000 # 5000 kbps
}
return bandwidths.get(res, 0)
Explanation
Define Resolutions: We define our target resolutions in the
RESOLUTIONSdictionary, each with FFmpeg scaling options.Lambda Handler: The
lambda_handlerfunction is triggered on video upload. It downloads the video from S3, processes it, creates HLS streams, and uploads the resulting files.Generate Master Playlist: We create a master
.m3u8playlist that points to each resolution.Upload to S3: The processed files and the master playlist are uploaded to the designated S3 bucket location.
Step 3: Package and Deploy the Lambda Function
- Package Files: Place
ffmpegandlambda_function.pyin the same directory. Zip them together:
zip -r lambda_function.zip lambda_function.py ffmpeg
- Upload the Zip to S3: You can upload
lambda_function.zipdirectly to Lambda through the console, but if it’s large, it’s often better to upload it to an S3 bucket and point Lambda to it.
2. Set Up the Lambda Function:
In the AWS Lambda Console, create a new Lambda function.
Choose Python as the runtime.
Under Function code, select Upload from .zip file or point to the S3 location.
Set Handler to
lambda_function.lambda_handler.
3. Configure Environment:
Increase memory (e.g., 512MB) and set the timeout to a few minutes to handle longer video processing times.
Set up an S3 Trigger on your bucket so that this Lambda function is automatically invoked when a new video is uploaded.
4. Add IAM Role Permissions:
- Ensure the Lambda execution role has permissions to read and write to S3. Attach an S3 policy to allow
s3:GetObjectands3:PutObjectpermissions.
Step 4: Testing the Function
Upload a video file to your S3 bucket, and your Lambda function should process the video automatically. After processing, you should see HLS segments and the master playlist file in your S3 bucket under the processed/ prefix.
Sample S3 Event JSON for Testing
If you want to test directly from the Lambda console, you can use a sample S3 event payload:
{
"Records": [
{
"s3": {
"bucket": {
"name": "your-bucket-name"
},
"object": {
"key": "path/to/your-video.mp4"
}
}
}
]
}
Replace "your-bucket-name" and "path/to/your-video.mp4" with your actual S3 bucket name and file path.
Wrapping Up
This Lambda function setup will let you automatically create HLS streams for videos uploaded to an S3 bucket, making your videos accessible in adaptive quality. This approach is cost-effective and scales well since it leverages AWS Lambda and S3 storage.
Notes and Considerations
Cold Start and Resource Limits: FFmpeg can be demanding on resources. Be mindful of Lambda’s memory and timeout settings.
Debugging: Use
printstatements to log each step, which will appear in CloudWatch Logs.Testing on Local: Always test your FFmpeg commands locally before deploying them to Lambda.
With this setup, you now have a serverless video processing pipeline that can handle HLS streaming. This is a great solution for delivering high-quality video content that adjusts to users’ bandwidth in real-time.
Happy streaming!

